# Run this cell to set up packages for lecture.
from lec19_imports import *
Agenda¶
- Example: Jury selection
- Example: Is our coin fair?
- Hypothesis tests.
- Null and alternative hypotheses.
- Test statistics, and how to choose them.
Example: Jury selection¶
Swain vs. Alabama, 1965¶
- Robert Swain was a Black man convicted of crime in Talladega County, Alabama.
- He appealed the jury's decision all the way to the Supreme Court, on the grounds that Talladega County systematically excluded Black people from juries.
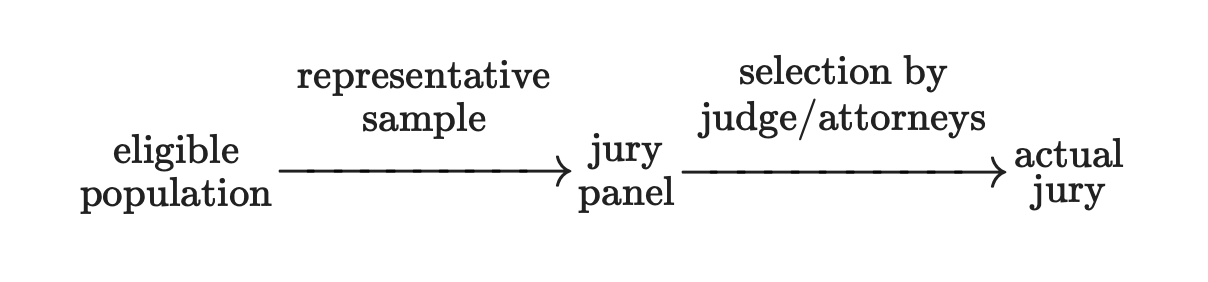
- At the time, only men 21 years or older were allowed to serve on juries. 26% of this eligible population was Black.
- But of the 100 men on Robert Swain's jury panel, only 8 were Black.
Supreme Court ruling¶
- About disparities between the percentages in the eligible population and the jury panel, the Supreme Court wrote:
"... the overall percentage disparity has been small...”
- The Supreme Court denied Robert Swain’s appeal and he was sentenced to life in prison.
- We now have the tools to show quantitatively that the Supreme Court's claim was misguided.
- This "overall percentage disparity" turns out to be not so small, and is an example of racial bias.
- Jury panels were often made up of people in the jury commissioner's professional and social circles.
- Of the 8 Black men on the jury panel, none were selected to be part of the actual jury.
Setup¶
- Model: Jury panels consist of 100 men, randomly chosen from a population that is 26% Black.
- Observation: On the actual jury panel, only 8 out of 100 men were Black.
- Question: Does the model explain the observation?
Our approach: Simulation¶
- We'll start by assuming that the model is true.
- We'll generate many jury panels using this assumption.
- We'll count the number of Black men in each simulated jury panel to see how likely it is for a random panel to contain 8 or fewer Black men.
- If we see 8 or fewer Black men often, then the model seems reasonable.
- If we rarely see 8 or fewer Black men, then the model may not be reasonable.
- Run an experiment once to generate one value of our chosen statistic.
- In this case, sample 100 people randomly from a population that is 26% Black, and count the number of Black men (statistic).
- Run the experiment many times, generating many values of the statistic, and store these statistics in an array.
- Visualize the resulting empirical distribution of the statistic.
Step 1 – Running the experiment once¶
- How do we randomly sample a jury panel?
np.random.choicewon't help us, because we don't know how large the eligible population is.
- The function
np.random.multinomialhelps us sample at random from a categorical distribution.
np.random.multinomial(sample_size, pop_distribution)
np.random.multinomialsamples at random from the population, with replacement, and returns a random array containing counts in each category.pop_distributionneeds to be an array containing the probabilities of each category.
Step 1 – Running the experiment once¶
In our case, a randomly selected member of our population is Black with probability 0.26 and not Black with probability 1 - 0.26 = 0.74.
demographics = [0.26, 0.74]
Each time we run the following cell, we'll get a new random sample of 100 people from this population.
- The first element of the resulting array is the number of Black men in the sample.
- The second element is the number of non-Black men in the sample.
np.random.multinomial(100, demographics)
array([30, 70])
Step 1 – Running the experiment once¶
We also need to calculate the statistic, which in this case is the number of Black men in the random sample of 100.
np.random.multinomial(100, demographics)[0]
20
Step 2 – Repeat the experiment many times¶
- Let's run 10,000 simulations.
- We'll keep track of the number of Black men in each simulated jury panel in the array
counts.
counts = np.array([])
for i in np.arange(10000):
new_count = np.random.multinomial(100, demographics)[0]
counts = np.append(counts, new_count)
counts
array([26., 20., 27., ..., 25., 28., 20.])
Step 3 – Visualize the resulting distribution¶
Was a jury panel with 8 Black men suspiciously unusual?
(bpd.DataFrame().assign(count_black_men=counts)
.plot(kind='hist', bins = np.arange(9.5, 45, 1),
density=True, ec='w', figsize=(10, 5),
title='Empiricial Distribution of the Number of Black Men in Simulated Jury Panels of Size 100'));
observed_count = 8
plt.axvline(observed_count, color='pink', linewidth=4, label='Observed Number of Black Men in Actual Jury Panel')
plt.legend();

# In 10,000 random experiments, the panel with the fewest Black men had how many?
counts.min()
11.0
Conclusion¶
- Our simulation shows that there's essentially no chance that a random sample of 100 men drawn from a population in which 26% of men are Black will contain 8 or fewer Black men.
- As a result, it seems that the model we proposed – that the jury panel was drawn at random from the eligible population – is flawed.
- There were likely factors other than chance that explain why there were only 8 Black men on the jury panel.
Example: Is our coin fair?¶
Example: Is our coin fair?¶
Let's suppose we find a coin on the ground and we aren't sure whether it's a fair coin.
Out of curiosity (and boredom), we flip it 400 times.
flips_400 = bpd.read_csv('data/flips-400.csv')
flips_400
| flip | outcome | |
|---|---|---|
| 0 | 1 | Tails |
| 1 | 2 | Tails |
| 2 | 3 | Tails |
| ... | ... | ... |
| 397 | 398 | Heads |
| 398 | 399 | Heads |
| 399 | 400 | Tails |
400 rows × 2 columns
flips_400.groupby('outcome').count()
| flip | |
|---|---|
| outcome | |
| Heads | 188 |
| Tails | 212 |
- Question: Does our coin look like a fair coin, or not?
How "weird" is it to flip a fair coin 400 times and see only 188 heads?
- This question is posed similarly to the question "were jury panels selected at random from the eligible population?"
Hypothesis tests¶
In the examples we've seen so far, our goal has been to choose between two views of the world, based on data in a sample.
"This jury panel was selected at random" or "this jury panel was not selected at random, since there weren't enough Black men on it."
"This coin is fair" or "this coin is not fair."
- A hypothesis test chooses between two views of how data were generated, based on data in a sample.
- The views are called hypotheses.
- The test picks the hypothesis that is better supported by the observed data; it doesn't guarantee that either hypothesis is correct.
Null and alternative hypotheses¶
- In our current example, our two hypotheses are "this coin is fair" and "this coin is not fair."
- In a hypothesis test:
- One of the hypotheses needs to be a well-defined probability model about how the data was generated, so that we can use it for simulation. This hypothesis is called the null hypothesis.
- The alternative hypothesis, then, is a different view about how the data was generated.
- We can simulate
nflips of a fair coin usingnp.random.multinomial(n, [0.5, 0.5]), but we can't simulatenflips of an unfair coin.
What does "unfair" mean? Does it flip heads with probability 0.51? 0.03?
- As such, "this coin is fair" is null hypothesis, and "this coin is not fair" is our alternative hypothesis.
Test statistics¶
- Once we've established our null and alternative hypotheses, we'll start by assuming the null hypothesis is true.
- Then, repeatedly, we'll generate samples under the assumption the null hypothesis is true (i.e. "under the null").
In the jury panel example, we repeatedly drew samples from a population that was 26% Black. In our current example, we'll repeatedly flip a fair coin 400 times.
- For each sample, we'll calculate a single number – that is, a statistic.
In the jury panel example, this was the number of Black men. In our current example, a reasonable choice is the number of heads.
- This single number is called the test statistic since we use it when "testing" which viewpoint the data better supports.
Think of the test statistic a number you write down each time you perform an experiment.
- The test statistic evaluated on our observed data is called the observed statistic.
In our current example, the observed statistic is 188.
- Our hypothesis test boils down to checking whether our observed statistic is a "typical value" in the distribution of our test statistic.
Simulating under the null¶
- Since our null hypothesis is "this coin is fair", we'll repeatedly flip a fair coin 400 times.
- Since our test statistic is the number of heads, in each set of 400 flips, we'll count the number of heads.
- Doing this will give us an empirical distribution of our test statistic.
# Computes a single simulated test statistic.
np.random.multinomial(400, [0.5, 0.5])[0]
196
# Computes 10,000 simulated test statistics.
results = np.array([])
for i in np.arange(10000):
result = np.random.multinomial(400, [0.5, 0.5])[0]
results = np.append(results, result)
results
array([204., 208., 198., ..., 206., 214., 184.])
Visualizing the empirical distribution of the test statistic¶
Let's visualize the empirical distribution of the test statistic $\text{number of heads}$.
bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(160, 240, 4),
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of the Number of Heads in 400 Flips of a Fair Coin');
plt.legend();

If we observed close to 200 heads, we'd think our coin is fair.
There are two cases in which we'd think our coin is unfair:
- If we observed lots of heads, e.g. 225.
- If we observed very few heads, e.g. 172.
This means that the histogram above is divided into three regions, where two of them mean the same thing (we think our coin is unfair).
It would be a bit simpler if we had a histogram that was divided into just two regions. How do we create such a histogram?
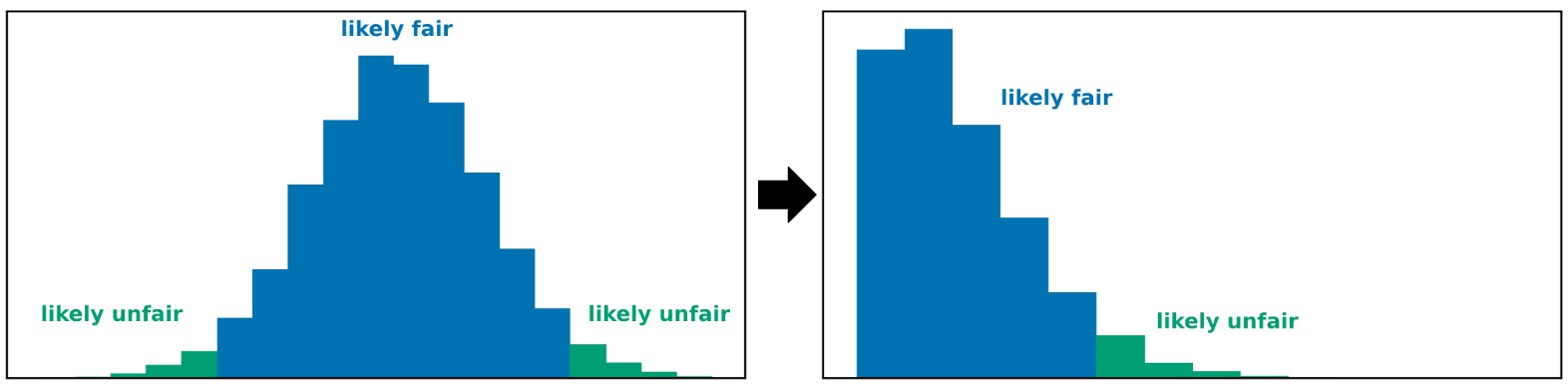
Choosing a test statistic¶
- We'd like our test statistic to be such that:
- Large observed values side with one hypothesis.
- Small observed values side with the other hypothesis.
- In this case, our statistic should capture how far our number of heads is from that of a fair coin.
- One idea: $| \text{number of heads} - 200 |$.
- If we use this as our test statistic, the observed statistic is $| 188 - 200 | = 12$.
- By simulating, we can quantify whether 12 is a reasonable value of the test statistic, or if it's larger than we'd expect from a fair coin.
Simulating under the null, again¶
Let's define a function that computes a single value of our test statistic. We'll do this often moving forward.
def num_heads_from_200(arr):
return abs(arr[0] - 200)
num_heads_from_200([188, 212])
12
Now, we'll repeat the act of flipping a fair coin 10,000 times again. The only difference is the test statistic we'll compute each time.
results = np.array([])
for i in np.arange(10000):
result = num_heads_from_200(np.random.multinomial(400, [0.5, 0.5]))
results = np.append(results, result)
results
array([ 1., 1., 7., ..., 7., 14., 19.])
Visualizing the empirical distribution of the test statistic, again¶
Let's visualize the empirical distribution of our new test statistic, $| \text{number of heads} - 200 |$.
bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(0, 60, 4),
density=True, ec='w', figsize=(10, 5),
title=r'Empirical Distribution of | Num Heads - 200 | in 400 Flips of a Fair Coin');
plt.axvline(12, color='pink', linewidth=4, label='observed statistic (12)')
plt.legend();

In black, we've drawn our observed statistic, 12. Does 12 seem like a reasonable value of the test statistic – that is, how rare was it to see a test statistic of 12 or larger in our simulations?
Drawing a conclusion¶
- It's not uncommon for the test statistic to be 12, or even higher, when flipping a fair coin 400 times. So it looks like our observed coin flips could have come from a fair coin.
- We are not saying that the coin is definitely fair, just that it's reasonably plausible that the coin is fair.
- More generally, if we frequently see values in the empirical distribution of the test statistic that are as or more extreme than our observed statistic, the null hypothesis seems plausible. In this case, we fail to reject the null hypothesis.
- If we rarely see values as extreme as our observed statistic, we reject the null hypothesis.
- Lingering question: How do we determine where to draw the line between "fail to reject" and "reject"?
- The answer is coming soon.
Our choice of test statistic depends on our alternative hypothesis!¶
- Suppose that our alternative hypothesis is now "this coin is biased towards tails."
- Now, the test statistic $| \text{number of heads} - 200 |$ won't work. Why not?
- In our current example, the value of the statistic $| \text{number of heads} - 200 |$ is 12. However, given just this information, we can't tell whether we saw:
- 188 heads (212 tails), which would be evidence that the coin is biased towards tails.
- 212 heads (188 tails), which would not be evidence that the coin is biased towards tails.
- As such, with this alternative hypothesis, we need another test statistic.
- Idea: $\text{number of heads}$.
- Small observed values side with the alternative hypothesis ("this coin is biased towards tails").
- Large observed values side with the null hypothesis ("this coin is fair").
- We could also use $\text{number of tails}$.
Simulating under the null, one more time¶
Since we're using the number of heads as our test statistic again, our simulation code is the same as it was originally.
results = np.array([])
for i in np.arange(10000):
result = np.random.multinomial(400, [0.5, 0.5])[0]
results = np.append(results, result)
results
array([203., 186., 188., ..., 179., 205., 191.])
Visualizing the empirical distribution of the test statistic, one more time¶
Let's visualize the empirical distribution of the test statistic $\text{number of heads}$, one more time.
bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(160, 240, 4),
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of the Number of Heads in 400 Flips of a Fair Coin');
plt.axvline(188, color='pink', linewidth=4, label='observed statistic (188)')
plt.legend();

- We frequently saw 188 or fewer heads in 400 flips of a fair coin; our observation doesn't seem to be that rare.
- As such, the null hypothesis seems plausible, so we fail to reject the null hypothesis.
Questions to consider before choosing a test statistic¶
- Key idea: Our choice of test statistic depends on the pair of viewpoints we want to decide between.
- Our test statistic should be such that high observed values lean towards one hypothesis and low observed values lean towards the other.
- We will avoid test statistics where both high and low observed values lean towards one viewpoint and observed values in the middle lean towards the other.
- In other words, we will avoid "two-sided" tests.
- To do so, we can take an absolute value.
- In our recent exploration, the null hypothesis was "the coin is fair."
- When the alternative hypothesis was "the coin is biased," the test statistic we chose was $$|\text{number of heads} - 200 |.$$
- When the alternative hypothesis was "the coin is biased towards tails," the test statistic we chose was $$\text{number of heads}.$$
Summary, next time¶
Summary¶
- In assessing a model, we are choosing between one of two viewpoints, or hypotheses.
- The null hypothesis must be a well-defined probability model about how the data was generated.
- The alternative hypothesis can be any other viewpoint about how the data was generated.
- To test a pair of hypotheses, we:
- Simulate the experiment many times under the assumption that the null hypothesis is true.
- Compute a test statistic on each of the simulated samples, as well as on the observed sample.
- Look at the resulting empirical distribution of test statistics and see where the observed test statistic falls. If it seems like an atypical value (too large or too small), we reject the null hypothesis; otherwise, we fail to reject the null.
- When selecting a test statistic, we want to choose a quantity that helps us distinguish between the two hypotheses, in such a way that large observed values favor one hypothesis and small observed values favor the other.
Next time¶
We'll look more closely at how to draw a conclusion from a hypothesis test and come up with a more precise definition of being "consistent" with the empirical distribution of test statistics generated according to the model.