# Run this cell to set up packages for lecture.
from lec08_imports import *
Agenda¶
- Functions.
- Applying functions to DataFrames.
- Example: Student names.
Reminder: Use the DSC 10 Reference Sheet.
Functions¶
Defining functions¶
- We've learned how to do quite a bit in Python:
- Manipulate arrays, Series, and DataFrames.
- Perform operations on strings.
- Create visualizations.
- But so far, we've been restricted to using existing functions (e.g.
max,np.sqrt,len) and methods (e.g..groupby,.assign,.plot).
Motivation¶
- Question: Create an array containing all the multiples of 10, in ascending order, that appear on the multiplication table below.
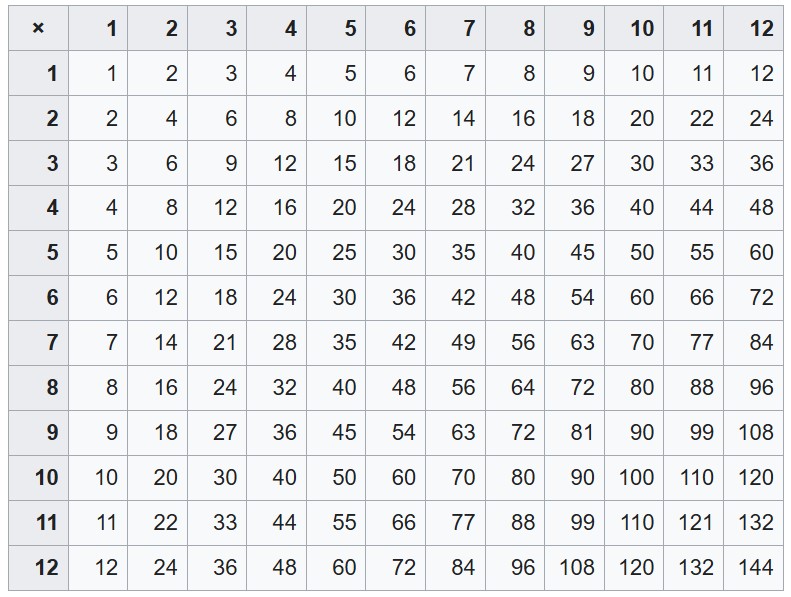
multiples_of_10 = ...
multiples_of_10
Ellipsis
- Question: Create an array containing all the multiples of 8, in increasing order, that appear on the multiplication table.
multiples_of_8 = ...
multiples_of_8
Ellipsis
More generally¶
What if we want to find the multiples of some other number, k? We can copy-paste and change some numbers, but that is prone to error.
multiples_of_5 = ...
multiples_of_5
Ellipsis
It turns out that we can define our own "multiples" function just once, and re-use it many times for different values of k. 🔁
def multiples(k):
'''This function returns the
first twelve multiples of k.'''
return np.arange(k, 13*k, k)
multiples(8)
array([ 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96])
multiples(5)
array([ 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60])
Note that we only had to specify how to calculate multiples a single time!
Functions¶
Functions are a way to divide our code into small subparts to prevent us from writing repetitive code. Each time we define our own function in Python, we will use the following pattern.
show_def()
Functions are "recipes"¶
- Functions take in inputs, known as arguments, do something, and produce some outputs.
- The beauty of functions is that you don't need to know how they are implemented in order to use them!
- For instance, you've been using the function
bpd.read_csvwithout knowing how it works. - This is the premise of the idea of abstraction in computer science – you'll hear a lot about this if you take DSC 20.
- For instance, you've been using the function
multiples(7)
array([ 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84])
multiples(-2)
array([ -2, -4, -6, -8, -10, -12, -14, -16, -18, -20, -22, -24])
Parameters and arguments¶
triple has one parameter, x.
def triple(x):
return x * 3
When we call triple with the argument 5, within the body of triple, x means 5.
triple(5)
15
We can call triple with other arguments, even strings!
triple(7 + 8)
45
triple('triton')
'tritontritontriton'
Scope 🩺¶
The names you choose for a function’s parameters are only known to that function (known as local scope). The rest of your notebook is unaffected by parameter names.
def triple(x):
return x * 3
triple(7)
21
Since we haven't defined an x outside of the body of triple, our notebook doesn't know what x means.
x
5.0
We can define an x outside of the body of triple, but that doesn't change how triple works.
x = 15
# When triple(12) is called, you can pretend
# there's an invisible line inside the body of x
# that says x = 12.
# The x = 15 above is ignored.
triple(12)
36
Functions can take 0 or more arguments¶
Functions can take any number of arguments.
greeting takes no arguments.
def greeting():
return 'Hi! 👋'
greeting()
'Hi! 👋'
custom_multiples takes two arguments!
def custom_multiples(k, how_many):
'''This function returns the
first how_many multiples of k.'''
return np.arange(k, (how_many + 1)*k, k)
custom_multiples(10, 7)
array([10, 20, 30, 40, 50, 60, 70])
custom_multiples(2, 100)
array([ 2, 4, 6, ..., 196, 198, 200])
Functions don't run until you call them!¶
The body of a function is not run until you use (call) the function.
Here, we can define where_is_the_error without seeing an error message.
def where_is_the_error(something):
'''A function to illustrate that errors don't occur
until functions are executed (called).'''
return (1 / 0) + something
It is only when we call where_is_the_error that Python gives us an error message.
where_is_the_error(5)
--------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) Cell In[155], line 1 ----> 1 where_is_the_error(5) Cell In[154], line 4, in where_is_the_error(something) 1 def where_is_the_error(something): 2 '''A function to illustrate that errors don't occur 3 until functions are executed (called).''' ----> 4 return (1 / 0) + something ZeroDivisionError: division by zero
Example: first_name¶
Let's create a function called first_name that takes in someone's full name and returns their first name. Example behavior is shown below.
>>> first_name('Pradeep Khosla')
'Pradeep'
Hint: Use the string method .split.
General strategy for writing functions:
- First, try and get the behavior to work on a single example.
- Then, encapsulate that behavior inside a function.
'Pradeep Khosla'.split(' ')[0]
'Pradeep'
def first_name(full_name):
'''Returns the first name given a full name.'''
return full_name.split(' ')[0]
first_name('Pradeep Khosla')
'Pradeep'
# What if there are three names?
first_name('Chancellor Pradeep Khosla')
'Chancellor'
Returning¶
- The
returnkeyword specifies what the output of your function should be, i.e. what a call to your function will evaluate to. - Some functions don't have any output and don't use
return.- If you want to be able to save the output of your function to a variable, you must use
return!
- If you want to be able to save the output of your function to a variable, you must use
- Be careful:
printandreturnwork differently!
def pythagorean(a, b):
'''Computes the hypotenuse length of a right triangle with legs a and b.'''
c = (a ** 2 + b ** 2) ** 0.5
print(c)
x = pythagorean(3, 4)
5.0
# No output – why?
x
# Errors – why?
x + 10
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[163], line 2 1 # Errors – why? ----> 2 x + 10 TypeError: unsupported operand type(s) for +: 'NoneType' and 'int'
def better_pythagorean(a, b):
'''Computes the hypotenuse length of a right triangle with legs a and b,
and actually returns the result.
'''
c = (a ** 2 + b ** 2) ** 0.5
return c
x = better_pythagorean(3, 4)
x
5.0
x + 10
15.0
Returning¶
Once a function executes a return statement, it stops running.
def motivational(quote):
return 0
print("Here's a motivational quote:", quote)
motivational('Fall seven times and stand up eight.')
0
Applying functions to DataFrames¶
DSC 10 student data¶
The DataFrame roster contains the names and colleges of all students enrolled in DSC 10 this term. The first names are real, while the last names have been anonymized for privacy.
roster = bpd.read_csv('data/roster-anon.csv')
roster
| name | college | |
|---|---|---|
| 0 | Aliya Btgdct | SI |
| 1 | Adrian Nchqxj | EI |
| 2 | Jocelyn Tkafna | TH |
| ... | ... | ... |
| 71 | Zihan Mirkem | SI |
| 72 | Ruochen Tnxprc | TH |
| 73 | Cathy Fdbekb | WA |
74 rows × 2 columns
Example: Common first names¶
What is the most common first name among DSC 10 students? (Any guesses?)
roster
| name | college | |
|---|---|---|
| 0 | Aliya Btgdct | SI |
| 1 | Adrian Nchqxj | EI |
| 2 | Jocelyn Tkafna | TH |
| ... | ... | ... |
| 71 | Zihan Mirkem | SI |
| 72 | Ruochen Tnxprc | TH |
| 73 | Cathy Fdbekb | WA |
74 rows × 2 columns
- Problem: We can't answer that right now, since we don't have a column with first names. If we did, we could group by it.
- Solution: Use our function that extracts first names on every element of the
'name'column.
Using our first_name function¶
Somehow, we need to call first_name on every student's 'name'.
roster
| name | college | |
|---|---|---|
| 0 | Aliya Btgdct | SI |
| 1 | Adrian Nchqxj | EI |
| 2 | Jocelyn Tkafna | TH |
| ... | ... | ... |
| 71 | Zihan Mirkem | SI |
| 72 | Ruochen Tnxprc | TH |
| 73 | Cathy Fdbekb | WA |
74 rows × 2 columns
roster.get('name').iloc[0]
'Aliya Btgdct'
first_name(roster.get('name').iloc[0])
'Aliya'
first_name(roster.get('name').iloc[1])
'Adrian'
Ideally, there's a better solution than doing this hundreds of times...
.apply¶
- To apply the function
func_nameto every element of column'col'in DataFramedf, use
df.get('col').apply(func_name)
- The
.applymethod is a Series method.- Important: We use
.applyon Series, not DataFrames. - The output of
.applyis also a Series.
- Important: We use
- Pass just the name of the function – don't call it!
- Good ✅:
.apply(first_name). - Bad ❌:
.apply(first_name()).
- Good ✅:
roster.get('name')
0 Aliya Btgdct
1 Adrian Nchqxj
2 Jocelyn Tkafna
...
71 Zihan Mirkem
72 Ruochen Tnxprc
73 Cathy Fdbekb
Name: name, Length: 74, dtype: object
roster.get('name').apply(first_name)
0 Aliya
1 Adrian
2 Jocelyn
...
71 Zihan
72 Ruochen
73 Cathy
Name: name, Length: 74, dtype: object
Example: Common first names¶
roster = roster.assign(
first=roster.get('name').apply(first_name)
)
roster
| name | college | first | |
|---|---|---|---|
| 0 | Aliya Btgdct | SI | Aliya |
| 1 | Adrian Nchqxj | EI | Adrian |
| 2 | Jocelyn Tkafna | TH | Jocelyn |
| ... | ... | ... | ... |
| 71 | Zihan Mirkem | SI | Zihan |
| 72 | Ruochen Tnxprc | TH | Ruochen |
| 73 | Cathy Fdbekb | WA | Cathy |
74 rows × 3 columns
Now that we have a column containing first names, we can find the distribution of first names.
name_counts = (
roster
.groupby('first')
.count()
.sort_values('name', ascending=False)
.get(['name'])
)
name_counts
| name | |
|---|---|
| first | |
| Adrian | 2 |
| Cathy | 2 |
| Tanmayi | 1 |
| ... | ... |
| Ghaida | 1 |
| Frank | 1 |
| Zuoyuan | 1 |
72 rows × 1 columns
Activity¶
Below:
- Create a bar chart showing the number of students with each first name, but only include first names shared by at least two students.
- Determine the proportion of students in DSC 10 who have a first name that is shared by at least two students.
Hint: Start by defining a DataFrame with only the names in name_counts that appeared at least twice. You can use this DataFrame to answer both questions.
✅ Click here to see the solutions after you've tried it yourself.
shared_names = name_counts[name_counts.get('name') >= 2]
# Bar chart.
shared_names.sort_values('name').plot(kind='barh', y='name', figsize=(5, 8));
# Proportion = # students with a shared name / total # of students.
shared_names.get('name').sum() / roster.shape[0]
...
Ellipsis
...
Ellipsis
.apply works with built-in functions, too!¶
name_counts.get('name')
first
Adrian 2
Cathy 2
Tanmayi 1
..
Ghaida 1
Frank 1
Zuoyuan 1
Name: name, Length: 72, dtype: int64
# Not necessarily meaningful, but doable.
name_counts.get('name').apply(np.log)
first
Adrian 0.69
Cathy 0.69
Tanmayi 0.00
...
Ghaida 0.00
Frank 0.00
Zuoyuan 0.00
Name: name, Length: 72, dtype: float64
Aside: Resetting the index¶
In name_counts, first names are stored in the index, which is not a Series. This means we can't use .apply on it.
name_counts.index
Index(['Adrian', 'Cathy', 'Tanmayi', 'Simmarjot', 'Shaun', 'Shahad', 'Sandhya',
'Sai', 'Sabrina', 'Ruochen', 'Ruchir', 'Pranaad', 'Prajan', 'Phoebe',
'Nuri', 'Niyati', 'Nadira', 'Siwoo', 'Tanuj', 'Mahi', 'Yingying',
'Zihan', 'Yunqing', 'Yunjae', 'Yufei', 'Yu', 'Yiquan', 'Yatheesh',
'Teresa', 'Xinran', 'Xiangyi', 'Veronica', 'Venkata', 'Vatsal',
'Tristan', 'Mukul', 'Maccall', 'Akhil', 'Arseniy', 'Chloe', 'Charles',
'Caokai', 'Bryan', 'Brendan', 'Ashley', 'Anusha', 'Edward', 'Anurag',
'Anish', 'Angelina', 'Ameya', 'Aliya', 'Alexis', 'Christian', 'Elisa',
'Kyle', 'Jocelyn', 'Kolya', 'Kenric', 'Kendall', 'Kelis', 'Julian',
'Joshua', 'Jason', 'Evie', 'Jasneh', 'Jacob', 'Isha', 'Grace', 'Ghaida',
'Frank', 'Zuoyuan'],
dtype='object', name='first')
name_counts.index.apply(len)
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In[184], line 1 ----> 1 name_counts.index.apply(max) AttributeError: 'Index' object has no attribute 'apply'
To help, we can use .reset_index() to turn the index of a DataFrame into a column, and to reset the index back to the default of 0, 1, 2, 3, and so on.
name_counts.reset_index().get('first').apply(len)
0 6
1 5
2 7
..
69 6
70 5
71 7
Name: first, Length: 72, dtype: int64
Example: Shared first names and colleges¶
- Suppose you're one of the students who has a first name that is shared with at least one other student.
- Let's try and determine whether someone in your college shares the same first name as you.
- For example, maybe
'Adrian Nchqxj'wants to see if there's another'Adian'in their college.
- For example, maybe
Strategy:
- Which college is
'Adrian Nchqxj'in? - How many people in that college have a first name of
'Adrian'?
roster
| name | college | first | |
|---|---|---|---|
| 0 | Aliya Btgdct | SI | Aliya |
| 1 | Adrian Nchqxj | EI | Adrian |
| 2 | Jocelyn Tkafna | TH | Jocelyn |
| ... | ... | ... | ... |
| 71 | Zihan Mirkem | SI | Zihan |
| 72 | Ruochen Tnxprc | TH | Ruochen |
| 73 | Cathy Fdbekb | WA | Cathy |
74 rows × 3 columns
which_college = roster[roster.get('name') == 'Adrian Nchqxj'].get('college').iloc[0]
which_college
'EI'
first_cond = roster.get('first') == 'Adrian' # A Boolean Series!
college_cond = roster.get('college') == which_college # A Boolean Series!
how_many = roster[first_cond & college_cond].shape[0]
how_many
2
Another function: shared_first_and_college¶
Let's create a function named shared_first_and_college. It will take in the full name of a student and return the number of students in their college with the same first name and college (including them).
Note: This is the first function we're writing that involves using a DataFrame within the function – this is fine!
def shared_first_and_college(name):
# First, find the row corresponding to that full name in roster.
# We're assuming that full names are unique.
row = roster[roster.get('name') == name]
# Then, get that student's first name and college.
first = row.get('first').iloc[0]
college = row.get('college').iloc[0]
# Now, find all the students with the same first name and college.
shared_info = roster[(roster.get('first') == first) & (roster.get('college') == college)]
# Return the number of such students.
return shared_info.shape[0]
shared_first_and_college('Adrian Nchqxj')
2
Now, let's add a column to roster that contains the values returned by shared_first_and_college.
roster = roster.assign(shared=roster.get('name').apply(shared_first_and_college))
roster
| name | college | first | shared | |
|---|---|---|---|---|
| 0 | Aliya Btgdct | SI | Aliya | 1 |
| 1 | Adrian Nchqxj | EI | Adrian | 2 |
| 2 | Jocelyn Tkafna | TH | Jocelyn | 1 |
| ... | ... | ... | ... | ... |
| 71 | Zihan Mirkem | SI | Zihan | 1 |
| 72 | Ruochen Tnxprc | TH | Ruochen | 1 |
| 73 | Cathy Fdbekb | WA | Cathy | 2 |
74 rows × 4 columns
Let's find all of the students who are in a college with someone that has the same first name as them.
roster[(roster.get('shared') >= 2)].sort_values('shared', ascending=False)
| name | college | first | shared | |
|---|---|---|---|---|
| 1 | Adrian Nchqxj | EI | Adrian | 2 |
| 21 | Adrian Senpzyt | EI | Adrian | 2 |
| 66 | Cathy Uglsgix | WA | Cathy | 2 |
| 73 | Cathy Fdbekb | WA | Cathy | 2 |
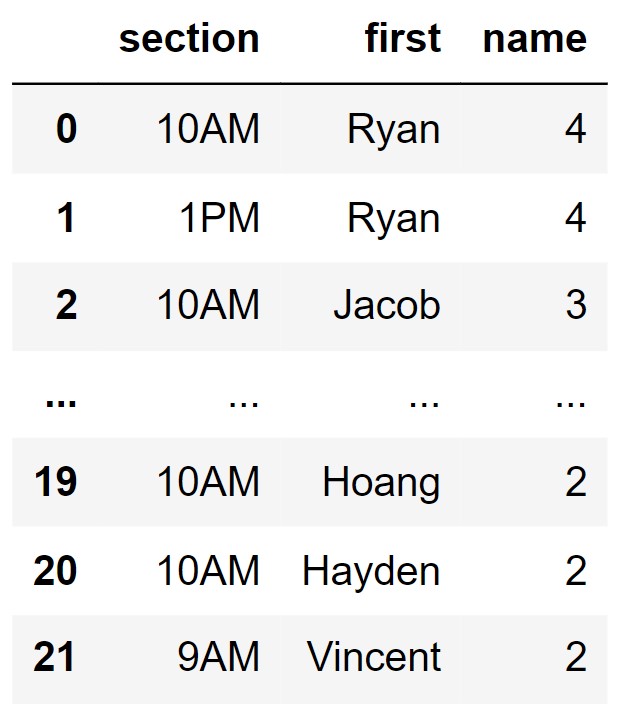
Sneak peek¶
While the DataFrame above contains the information we were looking for, it is not organized very conveniently and it is somewhat redundant.
Wouldn't it be great if we could create a DataFrame like the one below? We'll see how next time!
Activity¶
Find the longest first name in the class that is shared by at least two students in the same college.
Hint: You'll have to use both .assign and .apply.
✅ Click here to see the answer after you've tried it yourself.
with_len = roster.assign(name_len=roster.get('first').apply(len))
with_len[with_len.get('shared') >= 2].sort_values('name_len', ascending=False).get('first').iloc[0]
...
Ellipsis
Summary and Break¶
Summary¶
- Functions are a way to divide our code into small subparts to prevent us from writing repetitive code.
- The
.applymethod allows us to call a function on every single element of a Series, which usually comes from.getting a column of a DataFrame.
After the Break¶
More advanced DataFrame manipulations!