# Run this cell to set up packages for lecture.
from lec06_imports import *
%reload_ext pandas_tutor
Agenda¶
- Recap: Grouping.
- Adjusting columns.
- Why visualize?
- Terminology.
- Scatter plots.
- Line plots.
- Bar charts.
💡 Pro-Tip: Using Pandas Tutor¶
Pandas Tutor (built by Sam Lau) is pre-installed on DataHub. It visualizes the last line of a Jupyter cell. To use it, there are two steps:
- Add the line
%reload_ext pandas_tutorto the top of your notebook and run it (notice that we already did that in this notebook). - To visualize a cell, add
%%ptto the top of the cell:
%%pt
df = bpd.read_csv('data/dogs_small.csv')
df.get(['size', 'longevity']).groupby('size').mean()
💡 Pro-Tip: Using keyboard shortcuts¶
There are several keyboard shortcuts built into Jupyter Notebooks designed to help you save time. To see them, either click the keyboard button in the toolbar above or hit the H key on your keyboard (as long as you're not actively editing a cell).
Particularly useful shortcuts:
| Action | Keyboard shortcut |
|---|---|
| Run cell + jump to next cell | SHIFT + ENTER |
| Save the notebook | CTRL/CMD + S |
| Create new cell above/below | A/B |
| Delete cell | DD |
Recap: Grouping¶
The data: US states 🗽¶
We'll continue working with the same data from last time.
states = bpd.read_csv('data/states.csv')
states = states.assign(Density=states.get('Population') / states.get('Land Area'))
states = states.set_index('State')
states
| Region | Capital City | Population | Land Area | Party | Density | |
|---|---|---|---|---|---|---|
| State | ||||||
| Alabama | South | Montgomery | 5024279 | 50645 | Republican | 99.21 |
| Alaska | West | Juneau | 733391 | 570641 | Republican | 1.29 |
| Arizona | West | Phoenix | 7151502 | 113594 | Republican | 62.96 |
| ... | ... | ... | ... | ... | ... | ... |
| West Virginia | South | Charleston | 1793716 | 24038 | Republican | 74.62 |
| Wisconsin | Midwest | Madison | 5893718 | 54158 | Republican | 108.82 |
| Wyoming | West | Cheyenne | 576851 | 97093 | Republican | 5.94 |
50 rows × 6 columns
.groupby aggregates rows¶
In short, .groupby aggregates (collects) all rows with the same value in a specified column (e.g. 'Region') into a single row in the resulting DataFrame, combining the values from the different rows using an aggregation method (e.g. .sum()).
states.get(['Region', 'Population']).groupby('Region').sum()
| Population | |
|---|---|
| Region | |
| Midwest | 68985454 |
| Northeast | 57609148 |
| South | 125576562 |
| West | 78588572 |
Using .groupby in general¶
- Isolate the columns you'll need.
- Use
.get([...])to select the columns you'll need. - Rule of thumb:
- Choose a categorical column to group by (e.g.
Region). - Choose one or more columns to aggregate (e.g.
Population,Land Area, etc.). Most commonly, these are numerical columns. - The aggregation method should make sense for the data in the columns you want to aggregate (e.g.
.mean()works forintandfloatvalues, but not for strings).
- Choose a categorical column to group by (e.g.
- Use
- Make groups with
.groupby(categorical_column)..groupby(categorical_column)will gather rows which have the same value in the specified column.- In the resulting DataFrame, there will be one row for every unique value in that column.
- Follow up with an aggregation method.
- The aggregation method is applied within each group.
- The aggregation method is applied individually to each column.
- If it doesn't make sense to use the aggregation method on a column, you will get an error or nonsensical result. This is why we use
.getfirst, so we only aggregate the columns we want to!
- If it doesn't make sense to use the aggregation method on a column, you will get an error or nonsensical result. This is why we use
- Aggregation methods you should know:
.count(),.sum(),.mean(),.median(),.max(), and.min().- 🚨 Note: In this class, avoid using
.size()which is similar but not the same as.count().
- 🚨 Note: In this class, avoid using
(states
# Step 1
.get(['Region', 'Population'])
# Step 2
.groupby('Region')
# Step 3
.sum()
)
| Population | |
|---|---|
| Region | |
| Midwest | 68985454 |
| Northeast | 57609148 |
| South | 125576562 |
| West | 78588572 |
The role of .get¶
Observe what happens if we don't start with .get.
states.groupby('Region').sum()
| Capital City | Population | Land Area | Party | Density | |
|---|---|---|---|---|---|
| Region | |||||
| Midwest | SpringfieldIndianapolisDes MoinesTopekaLansing... | 68985454 | 750524 | DemocraticRepublicanRepublicanRepublicanRepubl... | 1298.78 |
| Northeast | HartfordAugustaBostonConcordTrentonAlbanyHarri... | 57609148 | 161912 | DemocraticDemocraticDemocraticDemocraticDemocr... | 4957.49 |
| South | MontgomeryLittle RockDoverTallahasseeAtlantaFr... | 125576562 | 868356 | RepublicanRepublicanDemocraticRepublicanRepubl... | 3189.37 |
| West | JuneauPhoenixSacramentoDenverHonoluluBoiseHele... | 78588572 | 1751054 | RepublicanRepublicanDemocraticDemocraticDemocr... | 881.62 |
states.groupby('Region').mean()
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/groupby.py:1944, in GroupBy._agg_py_fallback(self, how, values, ndim, alt) 1943 try: -> 1944 res_values = self._grouper.agg_series(ser, alt, preserve_dtype=True) 1945 except Exception as err: File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/ops.py:873, in BaseGrouper.agg_series(self, obj, func, preserve_dtype) 871 preserve_dtype = True --> 873 result = self._aggregate_series_pure_python(obj, func) 875 npvalues = lib.maybe_convert_objects(result, try_float=False) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/ops.py:894, in BaseGrouper._aggregate_series_pure_python(self, obj, func) 893 for i, group in enumerate(splitter): --> 894 res = func(group) 895 res = extract_result(res) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/groupby.py:2461, in GroupBy.mean.<locals>.<lambda>(x) 2458 else: 2459 result = self._cython_agg_general( 2460 "mean", -> 2461 alt=lambda x: Series(x, copy=False).mean(numeric_only=numeric_only), 2462 numeric_only=numeric_only, 2463 ) 2464 return result.__finalize__(self.obj, method="groupby") File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/series.py:6570, in Series.mean(self, axis, skipna, numeric_only, **kwargs) 6562 @doc(make_doc("mean", ndim=1)) 6563 def mean( 6564 self, (...) 6568 **kwargs, 6569 ): -> 6570 return NDFrame.mean(self, axis, skipna, numeric_only, **kwargs) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/generic.py:12485, in NDFrame.mean(self, axis, skipna, numeric_only, **kwargs) 12478 def mean( 12479 self, 12480 axis: Axis | None = 0, (...) 12483 **kwargs, 12484 ) -> Series | float: > 12485 return self._stat_function( 12486 "mean", nanops.nanmean, axis, skipna, numeric_only, **kwargs 12487 ) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/generic.py:12442, in NDFrame._stat_function(self, name, func, axis, skipna, numeric_only, **kwargs) 12440 validate_bool_kwarg(skipna, "skipna", none_allowed=False) > 12442 return self._reduce( 12443 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only 12444 ) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/series.py:6478, in Series._reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds) 6474 raise TypeError( 6475 f"Series.{name} does not allow {kwd_name}={numeric_only} " 6476 "with non-numeric dtypes." 6477 ) -> 6478 return op(delegate, skipna=skipna, **kwds) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/nanops.py:147, in bottleneck_switch.__call__.<locals>.f(values, axis, skipna, **kwds) 146 else: --> 147 result = alt(values, axis=axis, skipna=skipna, **kwds) 149 return result File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/nanops.py:404, in _datetimelike_compat.<locals>.new_func(values, axis, skipna, mask, **kwargs) 402 mask = isna(values) --> 404 result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs) 406 if datetimelike: File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/nanops.py:720, in nanmean(values, axis, skipna, mask) 719 the_sum = values.sum(axis, dtype=dtype_sum) --> 720 the_sum = _ensure_numeric(the_sum) 722 if axis is not None and getattr(the_sum, "ndim", False): File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/nanops.py:1701, in _ensure_numeric(x) 1699 if isinstance(x, str): 1700 # GH#44008, GH#36703 avoid casting e.g. strings to numeric -> 1701 raise TypeError(f"Could not convert string '{x}' to numeric") 1702 try: TypeError: Could not convert string 'SpringfieldIndianapolisDes MoinesTopekaLansingSaint PaulJefferson CityLincolnBismarckColumbusPierreMadison' to numeric The above exception was the direct cause of the following exception: TypeError Traceback (most recent call last) Cell In[14], line 1 ----> 1 states.groupby('Region').mean() File ~/dsc10/private/.venv/lib/python3.14/site-packages/babypandas/utils.py:20, in suppress_warnings.<locals>.wrapper(*args, **kwargs) 18 with warnings.catch_warnings(): 19 warnings.simplefilter("ignore") ---> 20 return func(*args, **kwargs) File ~/dsc10/private/.venv/lib/python3.14/site-packages/babypandas/bpd.py:1514, in DataFrameGroupBy.mean(self) 1510 """ 1511 Compute mean of group. 1512 """ 1513 f = _lift_to_pd(self._pd.mean) -> 1514 return f() File ~/dsc10/private/.venv/lib/python3.14/site-packages/babypandas/bpd.py:1596, in _lift_to_pd.<locals>.closure(*vargs, **kwargs) 1590 vargs = [x._pd if isinstance(x, types) else x for x in vargs] 1591 kwargs = { 1592 k: x._pd if isinstance(x, types) else x 1593 for (k, x) in kwargs.items() 1594 } -> 1596 a = func(*vargs, **kwargs) 1597 if isinstance(a, pd.DataFrame): 1598 return DataFrame(data=a) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/groupby.py:2459, in GroupBy.mean(self, numeric_only, engine, engine_kwargs) 2452 return self._numba_agg_general( 2453 grouped_mean, 2454 executor.float_dtype_mapping, 2455 engine_kwargs, 2456 min_periods=0, 2457 ) 2458 else: -> 2459 result = self._cython_agg_general( 2460 "mean", 2461 alt=lambda x: Series(x, copy=False).mean(numeric_only=numeric_only), 2462 numeric_only=numeric_only, 2463 ) 2464 return result.__finalize__(self.obj, method="groupby") File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/groupby.py:2005, in GroupBy._cython_agg_general(self, how, alt, numeric_only, min_count, **kwargs) 2002 result = self._agg_py_fallback(how, values, ndim=data.ndim, alt=alt) 2003 return result -> 2005 new_mgr = data.grouped_reduce(array_func) 2006 res = self._wrap_agged_manager(new_mgr) 2007 if how in ["idxmin", "idxmax"]: File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/internals/managers.py:1488, in BlockManager.grouped_reduce(self, func) 1484 if blk.is_object: 1485 # split on object-dtype blocks bc some columns may raise 1486 # while others do not. 1487 for sb in blk._split(): -> 1488 applied = sb.apply(func) 1489 result_blocks = extend_blocks(applied, result_blocks) 1490 else: File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/internals/blocks.py:395, in Block.apply(self, func, **kwargs) 389 @final 390 def apply(self, func, **kwargs) -> list[Block]: 391 """ 392 apply the function to my values; return a block if we are not 393 one 394 """ --> 395 result = func(self.values, **kwargs) 397 result = maybe_coerce_values(result) 398 return self._split_op_result(result) File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/groupby.py:2002, in GroupBy._cython_agg_general.<locals>.array_func(values) 1999 return result 2001 assert alt is not None -> 2002 result = self._agg_py_fallback(how, values, ndim=data.ndim, alt=alt) 2003 return result File ~/dsc10/private/.venv/lib/python3.14/site-packages/pandas/core/groupby/groupby.py:1948, in GroupBy._agg_py_fallback(self, how, values, ndim, alt) 1946 msg = f"agg function failed [how->{how},dtype->{ser.dtype}]" 1947 # preserve the kind of exception that raised -> 1948 raise type(err)(msg) from err 1950 dtype = ser.dtype 1951 if dtype == object: TypeError: agg function failed [how->mean,dtype->object]
Observations on grouping¶
- After grouping, the index changes. The new row labels are the group labels (i.e., the unique values in the column that we grouped on), sorted in ascending order.
💡 Pro-Tip: look for keywords "per," "for each," and "indexed by" when solving problems.
- The aggregation method is applied separately to each column. If it does not make sense to apply the aggregation method to a certain column, you will get an error or a nonsensical result.
- Since the aggregation method is applied to each column separately, the rows of the resulting DataFrame need to be interpreted with care.
- The column names don't make sense after grouping with the
.count()aggregation method.
states.groupby('Region').count()
| Capital City | Population | Land Area | Party | Density | |
|---|---|---|---|---|---|
| Region | |||||
| Midwest | 12 | 12 | 12 | 12 | 12 |
| Northeast | 9 | 9 | 9 | 9 | 9 |
| South | 16 | 16 | 16 | 16 | 16 |
| West | 13 | 13 | 13 | 13 | 13 |
Dropping, renaming, and reordering columns¶
Consider dropping unneeded columns and renaming columns as follows:
- Use
.assignto create a new column containing the same values as the old column(s). - Use
.drop(columns=list_of_column_labels)to drop the old column(s).- Alternatively, use
.get(list_of_column_labels)to keep only the columns in the given list. The columns will appear in the order you specify, so this is also useful for reordering columns!
- Alternatively, use
states_by_region = states.groupby('Region').count()
states_by_region = states_by_region.assign(
States=states_by_region.get('Capital City')
).get(['States'])
states_by_region
| States | |
|---|---|
| Region | |
| Midwest | 12 |
| Northeast | 9 |
| South | 16 |
| West | 13 |
Why visualize?¶
Little Women¶
In Lecture 1, we were able to answer questions about the plot of Little Women without having to read the novel and without having to understand Python code. Some of those questions included:
- Who is the main character?
- Which pair of characters gets married at the end?
We answered these questions from a data visualization alone!
bpd.read_csv('data/lw_counts.csv').plot(x='Chapter', linewidth=3.0);

Why visualize?¶
- Computers are better than humans at crunching numbers, but humans are better at identifying visual patterns.
- Visualizations allow us to understand lots of data quickly – they make it easier to spot trends and communicate our results with others.
- There are many types of visualizations; in this class, we'll look at scatter plots, line plots, bar charts, and histograms, but there are many others.
- The right choice depends on the type of data.
Terminology¶
Individuals and variables¶

- Individual (row): Person/place/thing for which data is recorded. Also called an observation.
- Variable (column): Something that is recorded for each individual. Also called a feature.
Types of variables¶
There are two main types of variables:
- Numerical: It makes sense to do arithmetic with the values.
- Categorical: Values fall into categories, that may or may not have some order to them.
Note that here, "variable" does not mean a variable in Python, but rather it means a column in a DataFrame.
Examples of numerical variables¶
- Salaries of NBA players 🏀.
- Individual: An NBA player.
- Variable: Their salary.
- Company's annual profit 💰.
- Individual: A company.
- Variable: Its annual profit.
- Flu shots administered per day 💉.
- Individual: Date.
- Variable: Number of flu shots administered on that date.
Examples of categorical variables¶
- Movie genres 🎬.
- Individual: A movie.
- Variable: Its genre.
- Zip codes 🏠.
- Individual: US resident.
- Variable: Zip code.
- Even though they look like numbers, zip codes are categorical (arithmetic doesn't make sense).
- Level of prior programming experience for students in DSC 10 🧑🎓.
- Individual: Student in DSC 10.
- Variable: Their level of prior programming experience, e.g. none, low, medium, or high.
- There is an order to these categories!
Concept Check ✅ – Answer at cc.dsc10.com¶
Which of these is not a numerical variable?
A. Fuel economy in miles per gallon.
B. Number of quarters at UCSD.
C. College at UCSD (Sixth, Seventh, etc).
D. Bank account number.
E. More than one of these are not numerical variables.
Types of visualizations¶
The type of visualization we create depends on the kinds of variables we're visualizing.
- Scatter plot: Numerical vs. numerical.
- Line plot: Sequential numerical (time) vs. numerical.
- Bar chart: Categorical vs. numerical.
- Histogram: Numerical.
- Will cover next time.
We may interchange the words "plot", "chart", and "graph"; they all mean the same thing.
Scatter plots¶
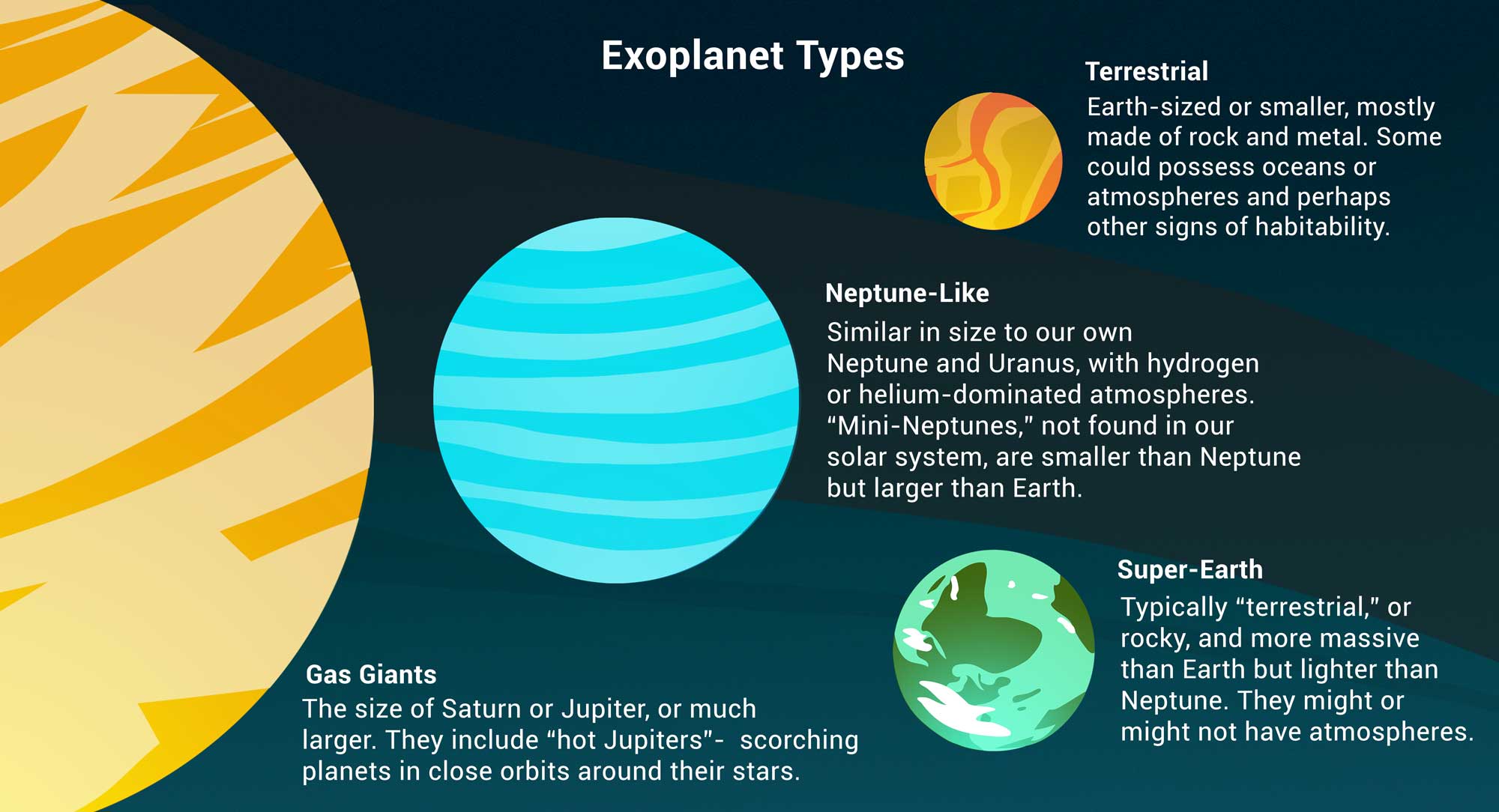
The data: exoplanets discovered by NASA 🪐¶
An exoplanet is a planet outside our solar system. NASA has discovered over 5,000 exoplanets so far in its search for signs of life beyond Earth. 👽
| Column | Contents |
|---|
'Distance'| Distance from Earth, in light years.
'Magnitude'| Apparent magnitude, which measures brightness in such a way that brighter objects have lower values.
'Type'| Categorization of planet based on its composition and size.
'Year'| When the planet was discovered.
'Detection'| The method of detection used to discover the planet.
'Mass'| The ratio of the planet's mass to Earth's mass.
'Radius'| The ratio of the planet's radius to Earth's radius.
exo = bpd.read_csv('data/exoplanets.csv').set_index('Name')
exo
| Distance | Magnitude | Type | Year | Detection | Mass | Radius | |
|---|---|---|---|---|---|---|---|
| Name | |||||||
| 11 Comae Berenices b | 304.0 | 4.72 | Gas Giant | 2007 | Radial Velocity | 6165.90 | 11.88 |
| 11 Ursae Minoris b | 409.0 | 5.01 | Gas Giant | 2009 | Radial Velocity | 4684.81 | 11.99 |
| 14 Andromedae b | 246.0 | 5.23 | Gas Giant | 2008 | Radial Velocity | 1525.58 | 12.65 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| YZ Ceti b | 12.0 | 12.07 | Terrestrial | 2017 | Radial Velocity | 0.70 | 0.91 |
| YZ Ceti c | 12.0 | 12.07 | Super Earth | 2017 | Radial Velocity | 1.14 | 1.05 |
| YZ Ceti d | 12.0 | 12.07 | Super Earth | 2017 | Radial Velocity | 1.09 | 1.03 |
5043 rows × 7 columns
Scatter plots¶
- What is the relationship between
'Distance'and'Magnitude'?
exo.plot(kind='scatter', x='Distance', y='Magnitude');

Further planets have greater
'Magnitude'(meaning they are less bright), which makes sense.The data appears curved because
'Magnitude'is measured on a logarithmic scale. A decrease of one unit in'Magnitude'corresponds to a 2.5 times increase in brightness.

Scatter plots¶
- Scatter plots visualize the relationship between two numerical variables.
- To create one from a DataFrame
df, use
df.plot(
kind='scatter',
x=x_column_for_horizontal,
y=y_column_for_vertical
)
- The resulting scatter plot has one point per row of
df. - If you put a semicolon after a call to
.plot, it will hide the weird text output that displays.
Zooming in 🔍¶
The majority of exoplanets are less than 10,000 light years away; if we'd like to zoom in on just these exoplanets, we can query before plotting.
exo[exo.get('Distance') < 10000].plot(kind='scatter', x='Distance', y='Magnitude');

Line plots 📉¶
Line plots¶
- How has the
'Magnitude'of newly discovered exoplanets changed over time?
# There were multiple exoplanets discovered each year.
# What operation can we apply to this DataFrame so that there is one row per year?
exo
| Distance | Magnitude | Type | Year | Detection | Mass | Radius | |
|---|---|---|---|---|---|---|---|
| Name | |||||||
| 11 Comae Berenices b | 304.0 | 4.72 | Gas Giant | 2007 | Radial Velocity | 6165.90 | 11.88 |
| 11 Ursae Minoris b | 409.0 | 5.01 | Gas Giant | 2009 | Radial Velocity | 4684.81 | 11.99 |
| 14 Andromedae b | 246.0 | 5.23 | Gas Giant | 2008 | Radial Velocity | 1525.58 | 12.65 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| YZ Ceti b | 12.0 | 12.07 | Terrestrial | 2017 | Radial Velocity | 0.70 | 0.91 |
| YZ Ceti c | 12.0 | 12.07 | Super Earth | 2017 | Radial Velocity | 1.14 | 1.05 |
| YZ Ceti d | 12.0 | 12.07 | Super Earth | 2017 | Radial Velocity | 1.09 | 1.03 |
5043 rows × 7 columns
- Let's calculate the average
'Magnitude'of all exoplanets discovered in each'Year'.
exo.get(['Year', 'Magnitude']).groupby('Year').mean()
| Magnitude | |
|---|---|
| Year | |
| 1995 | 5.45 |
| 1996 | 5.12 |
| 1997 | 5.41 |
| ... | ... |
| 2021 | 13.01 |
| 2022 | 10.62 |
| 2023 | 12.09 |
29 rows × 1 columns
(exo
.get(['Year', 'Magnitude'])
.groupby('Year')
.mean()
.plot(
kind='line',
y='Magnitude',
linewidth=3.0)
);

It looks like the brightest planets were discovered first, which makes sense.
NASA's Kepler space telescope began its nine-year mission in 2009, leading to a boom in the discovery of exoplanets.
Line plots¶
- Line plots show trends in numerical variables over time.
- To create one from a DataFrame
df, use
df.plot(
kind='line',
x=x_column_for_horizontal,
y=y_column_for_vertical
)
- To use the index as the x-axis, omit the
x=argument.- This doesn't work for scatterplots, but it works for most other plot types.
Bar charts 📊¶
Bar charts¶
- How big are each of the different
'Type's of exoplanets, on average?
exo
| Distance | Magnitude | Type | Year | Detection | Mass | Radius | |
|---|---|---|---|---|---|---|---|
| Name | |||||||
| 11 Comae Berenices b | 304.0 | 4.72 | Gas Giant | 2007 | Radial Velocity | 6165.90 | 11.88 |
| 11 Ursae Minoris b | 409.0 | 5.01 | Gas Giant | 2009 | Radial Velocity | 4684.81 | 11.99 |
| 14 Andromedae b | 246.0 | 5.23 | Gas Giant | 2008 | Radial Velocity | 1525.58 | 12.65 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| YZ Ceti b | 12.0 | 12.07 | Terrestrial | 2017 | Radial Velocity | 0.70 | 0.91 |
| YZ Ceti c | 12.0 | 12.07 | Super Earth | 2017 | Radial Velocity | 1.14 | 1.05 |
| YZ Ceti d | 12.0 | 12.07 | Super Earth | 2017 | Radial Velocity | 1.09 | 1.03 |
5043 rows × 7 columns
types = (exo
.get(['Type', 'Mass', 'Radius', 'Magnitude', 'Distance'])
.groupby('Type')
.mean()
)
types
| Mass | Radius | Magnitude | Distance | |
|---|---|---|---|---|
| Type | ||||
| Gas Giant | 1472.39 | 12.74 | 10.30 | 1096.40 |
| Neptune-like | 15.28 | 3.11 | 13.52 | 2189.02 |
| Super Earth | 5.81 | 1.58 | 13.85 | 1916.26 |
| Terrestrial | 1.62 | 0.85 | 13.45 | 1373.60 |
types.plot(kind='barh', y='Radius');

types.plot(kind='barh', y='Mass');

- It looks like the
'Gas Giant's are aptly named!
Bar charts¶
- Bar charts visualize the relationship between a categorical variable and a numerical variable.
- In a bar chart...
- The thickness and spacing of bars is arbitrary.
- The order of the categorical labels doesn't matter.
- To create one from a DataFrame
df, use
df.plot(
kind='barh',
x=categorical_column_name,
y=numerical_column_name
)
- The "h" in
'barh'stands for "horizontal".- It's easier to read labels this way.
- Note that in the previous chart, we set
y='Mass'even though mass is measured by x-axis length.
Bar charts and sorting¶
What are the most popular 'Detection' methods for discovering exoplanets?
# Count how many exoplanets are discovered by each detection method.
popular_detection = exo.groupby('Detection').count()
popular_detection
| Distance | Magnitude | Type | Year | Mass | Radius | |
|---|---|---|---|---|---|---|
| Detection | ||||||
| Astrometry | 1 | 1 | 1 | 1 | 1 | 1 |
| Direct Imaging | 50 | 50 | 50 | 50 | 50 | 50 |
| Disk Kinematics | 1 | 1 | 1 | 1 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... |
| Radial Velocity | 1019 | 1019 | 1019 | 1019 | 1019 | 1019 |
| Transit | 3914 | 3914 | 3914 | 3914 | 3914 | 3914 |
| Transit Timing Variations | 23 | 23 | 23 | 23 | 23 | 23 |
11 rows × 6 columns
# Give columns more meaningful names and eliminate redundancy.
popular_detection = (popular_detection.assign(Count=popular_detection.get('Distance'))
.get(['Count'])
.sort_values(by='Count', ascending=False)
)
popular_detection
| Count | |
|---|---|
| Detection | |
| Transit | 3914 |
| Radial Velocity | 1019 |
| Direct Imaging | 50 |
| ... | ... |
| Astrometry | 1 |
| Disk Kinematics | 1 |
| Pulsar Timing | 1 |
11 rows × 1 columns
# Notice that the bars appear in the opposite order relative to the DataFrame.
popular_detection.plot(kind='barh', y='Count');

# Change "barh" to "bar" to get a vertical bar chart.
# These are harder to read, but the bars do appear in the same order as the DataFrame.
popular_detection.plot(kind='bar', y='Count');

Multiple plots on the same axes¶
Can we look at both the average 'Magnitude' and the average 'Radius' for each 'Type' at the same time?
types.get(['Magnitude', 'Radius']).plot(kind='barh');

How did we do that?
Overlaying plots¶
When calling .plot, if we omit the y=column_name argument, all other columns are plotted.
types
| Mass | Radius | Magnitude | Distance | |
|---|---|---|---|---|
| Type | ||||
| Gas Giant | 1472.39 | 12.74 | 10.30 | 1096.40 |
| Neptune-like | 15.28 | 3.11 | 13.52 | 2189.02 |
| Super Earth | 5.81 | 1.58 | 13.85 | 1916.26 |
| Terrestrial | 1.62 | 0.85 | 13.45 | 1373.60 |
types.plot(kind='barh');

Selecting multiple columns at once¶
Remember, to select multiple columns, use .get([column_1, ..., column_k]). This returns a DataFrame.
types
| Mass | Radius | Magnitude | Distance | |
|---|---|---|---|---|
| Type | ||||
| Gas Giant | 1472.39 | 12.74 | 10.30 | 1096.40 |
| Neptune-like | 15.28 | 3.11 | 13.52 | 2189.02 |
| Super Earth | 5.81 | 1.58 | 13.85 | 1916.26 |
| Terrestrial | 1.62 | 0.85 | 13.45 | 1373.60 |
types.get(['Magnitude', 'Radius'])
| Magnitude | Radius | |
|---|---|---|
| Type | ||
| Gas Giant | 10.30 | 12.74 |
| Neptune-like | 13.52 | 3.11 |
| Super Earth | 13.85 | 1.58 |
| Terrestrial | 13.45 | 0.85 |
types.get(['Magnitude', 'Radius']).plot(kind='barh');
Summary¶
Summary¶
- Visualizations make it easy to extract patterns from datasets.
- There are two main types of variables: categorical and numerical.
- The types of the variables we're visualizing inform our choice of which type of visualization to use.
- Today, we looked at scatter plots, line plots, and bar charts.
- Next time: histograms.